本記事は、dbt advent calendarの内容です。 qiita.com
オープンデータ+BiqQuery+dbt+Streamlitという構成で、東京都における犯罪ダッシュボードを作ってみました。
完成品とコードはこちら
今回は、dbtのチュートリアル的王道パターンを一通り使ってみることを目的にしているので、もし「こんな機能もつかってみては?」などあれば、是非ともコメントいただけると嬉しいです!
それでは、いってみましょう!
犯罪オープンデータとは?
今回は東京の公開データをメインで使用していきます。
今回の構成
構成は以下の通りです。
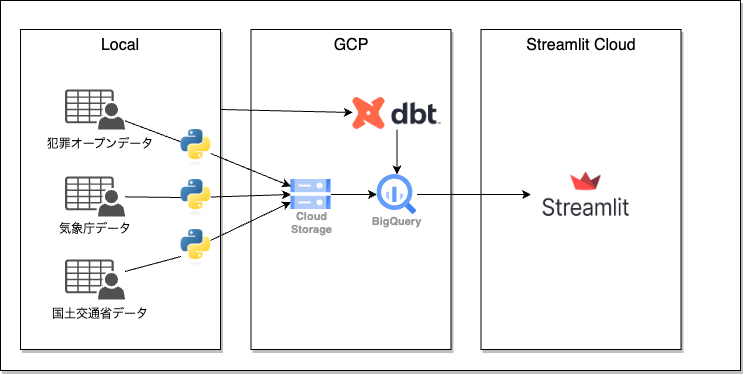
元データは以下の3つから取得しています。
上記データを取得後に、Pythonを使って前処理&cloud strageへのアップロード、そして、BigQueryの外部テーブルとしてテーブルを作成します。
dbtは、ローカル環境からBigQueryへ実行、streamlit cloudのウェブアプリからBigQueryのテーブルを参照するようにしました。
前処理
dbtはETLのT(変換)部分を得意とするため、ほぼ生データをアップロードしてもよいのですが、dbt処理で大変そうな部分は事前にPythonで処理をしておきます。ついでに、ファイル形式をparquetに変換しています。
犯罪オープンデータ
犯罪発生年と手口で1つのcsvになっています。今回は2018~2022年×7手口なので、全部で35ファイルを一つのテーブルとして扱っています。
各ファイルをスクレイピングでダウンロードし、GCSにアップロードしました。微妙に列名が違ったり、半角全角が混じっていたりするをPythonで下処理をしています。(日本語の表記揺れは森羅万象)
crime-visualizer/script/upload_crime_parquet.py at master · koy0208/crime-visualizer · GitHub
天気データ、緯度経度データ
この二つは、比較的綺麗に構造化されていたので、そのままの形でアップロードしました。
dbt
さて、いよいよdbtです。dbtとBiqQueryの設定は事前に済ましています。 www.medi-08-data-06.work
データリネージ
最終的なデータリネージは、こんな感じです。

本来は、集計にあわせて、さらに中間、マートテーブルを増やしておくべきですが、BIqQueryとStreamlitのレスポンスが遅いため、Streamlit上で、各種集計処理を行うようにしています。そのため、全データを結合した一つのマートのみを準備しています。
各層での処理は以下の通りです。
-
- 列の選択
- 必須データ欠損行のフィルター処理
-
- 新規列の追加
- 数値データを集計粒度にあわせたカテゴリに変換
-
- 3データを結合し、すべての集計粒度(ディメンション)を保持しておく。
- 住所と緯度経度マスターは、mart層に保持
テスト
dbtでは、テーブルごとにtestが実行できるのがよいところですよね。今回はuniqueやnot_nullを各テーブルに指定しています。また、犯罪データの"手口"の列の値が、想定した7つの手口データのみになっているかをチェックするテストもいれてみました。
データ品質を担保しつつ、モデリングできるなんて最高です。
- name: stg_tokyo_crimes columns: - name: tokyo_crimes_id tests: - not_null - unique - name: teguchi tests: - not_null - accepted_values: values: [ "ひったくり", "オートバイ盗", "自動車盗", "部品ねらい", "自動販売機ねらい", "車上ねらい", "自転車盗", ]
マクロ
データ処理にJinja のマクロを活用できるのもよいところ。
今回の場合は、以下の2つのマクロを使用しています。(再掲、日本語の表記揺れは森羅万象)
- 犯罪データと緯度経度データの結合keyである住所の漢数字を、アラビア数字に変換し正規化するマクロ
{% macro kanji_to_num(column_name) %}
replace(translate({{ column_name }}, '一二三四五六七八九', '123456789'), '十', '10')
{% endmacro %}
例として、"十九番地"は、"19番地"としたいところですが、上記の処理では"109番地"になってしまいます。
さらに精確に変換するには、より複雑なロジックが必要ですが、今回は目をつぶってください。m(_ _)m
- 欠損部分で、空白になっているパターンと
不明の文字列が入っているパターンを統一するため、空白文字をすべて不明にするマクロ
{% macro replace_null(column_name) %}
case when {{ column_name }} = '' then '不明' else {{ column_name }} end
{% endmacro %}
Streamlitとの接続
上記dbtで作成したマートテーブルは、Streamlitからアクセスできるように しておきます。接続方法は以下を参考にしています。
Connect Streamlit to Google BigQuery - Streamlit Docs
ダッシュボード完成
さて、Streamlitで見た目を整えて、Streamlit cloudにデプロイしたらダッシュボードの完成です!
ダッシュボードは、以下の2つを画面上部のタブで切り替えられるようにしています。
- 全体の概要ダッシュボード
- 被害者属性や外的因子と犯罪件数のクロス集計をみることができる詳細ダッシュボード
全体
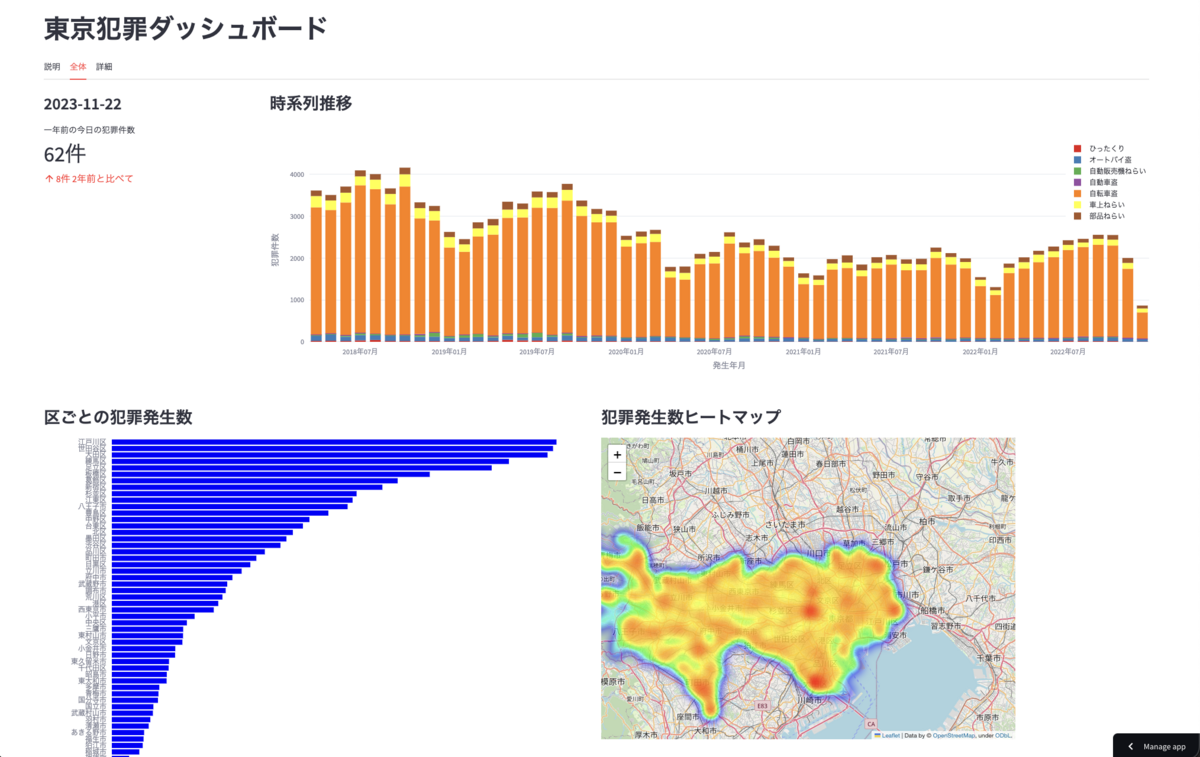
- ぱっと見の示唆
- 犯罪件数は年々減少傾向にある
- 年周期があり、冬は件数が減る傾向にある。
- 7手口の中では、自転車盗難が多くを占める
- 江戸川区、世田谷区、大田区が件数ワースト3位
- ヒートマップで見ると駅周辺での発生が多い
詳細
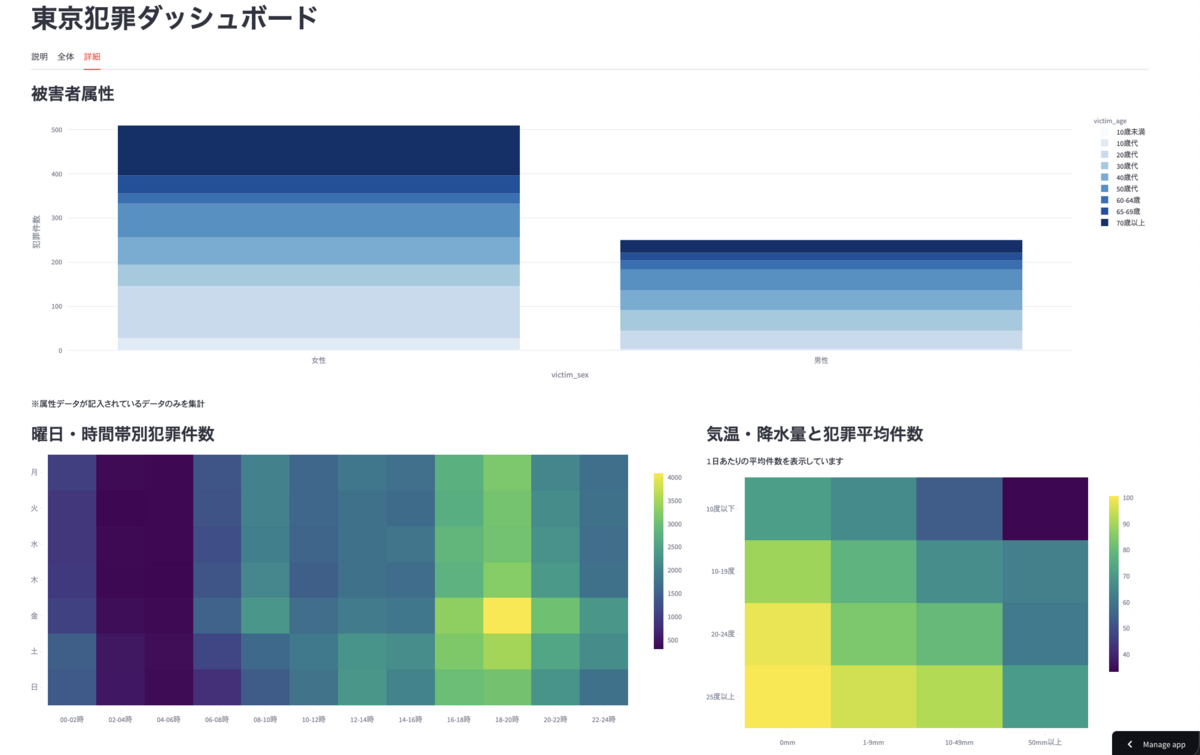
- ぱっと見の示唆
- 被害者の多くは女性
- 夕方に発生しやすく、特に金曜日の18時-20時は発生しやすい
- 平均気温が高く(おそらく季節が交絡)、降水量が少ない日に発生しやすい
自転車盗難が多くを占めるため、上記の示唆は、自転車の利用状況と強く関連していそうですね。気候が温かく、よく晴れた日ほど自転車に乗る人がおおく、発生数も増えているのかもしれません。男女での自転車利用状況の違いなども影響しているかもしれませんね。
まとめ
今回は、とりあえずdbtを一通り使ってアウトプットを出すことを目標にしました。データモデリングの観点でも、まだまだ改善の余地はありそうです。
最終アウトプットをイメージしつつ、適切な集計粒度でモデリングするというのは、簡単なようで、奥が深いですね。
参考
dbtの公式入門ドキュメント『Quickstart for dbt Cloud and BigQuery』を実践してみた #dbt | DevelopersIO
Best practice guides | dbt Developer Hub
※本記事は筆者が個人的に学んだこと感じたことをまとめた記事になります。所属する組織の意見・見解とは無関係です。