
Kimbalのディメンショナルモデリングは、データウェハウスのデータモデリングの中でも、広く採用されている手法で、近年のData Vault 2.0の基本となる考え方となっています。
こちらは、ディメンショナルモデリングのバイブルです↓
")
トランザクション処理に最適な3NF(第三正規化)などの設計とはことなり、ビジネスプロセスをモデルに組み込むことで、シンプルなクエリでデータ分析ができるようになります。
今回は、そんなディメンショナルモデリングをdbtで実践するためのチュートリアルをやっていきます。
setup
データベース
はじめにデータウェハウスを構築するDBを設定します。記事内では、 DuckDB or PosgreSQLを直接ローカルPCへインストールする方法が載っていますが、今回はdockerで環境を設定します。
また、チュートリアル内では、postgresユーザーを使用しており、adventureworksというデータベースも必要なので、init.sqlでコンテナ立ち上げ時に設定してしまいます。
以下2つのファイルを準備します。
docker-compose.yml
version: '3' services: postgres: image: postgres:latest restart: always ports: - 5432:5432 environment: POSTGRES_USER: admin POSTGRES_PASSWORD: admin volumes: - ./postgres:/var/lib/postgresql/data - ./init.sql:/docker-entrypoint-initdb.d/init.sql
init.sql
CREATE USER postgres WITH PASSWORD 'postgres'; -- ユーザー作成 CREATE DATABASE adventureworks;-- DB作成 GRANT ALL PRIVILEGES ON DATABASE adventureworks TO postgres; -- 権限付与
チュートリアルレポジトリの設定
チュートリアル通り設定していきます。プロファイルの設定(targetをpostgresに変更しておく)、dbt_utilsのインストール、seedの設定を行っています。
git clone https://github.com/Data-Engineer-Camp/dbt-dimensional-modelling.git cd dbt-dimensional-modelling/adventureworks pip install dbt-postgres dbt deps dbt seed --target postgres
adventureworks/profiles.yml
adventureworks: target: postgres outputs: duckdb: type: duckdb path: target/adventureworks.duckdb threads: 12 postgres: type: postgres host: localhost user: postgres password: postgres port: 5432 dbname: adventureworks schema: dbo threads: 12
少し中身をみてみます。
select * from person.countryregion limit 10; countryregioncode | modifieddate | name -------------------+---------------------+---------------------- AD | 2008-04-30 00:00:00 | Andorra AE | 2008-04-30 00:00:00 | United Arab Emirates AF | 2008-04-30 00:00:00 | Afghanistan AG | 2008-04-30 00:00:00 | Antigua and Barbuda AI | 2008-04-30 00:00:00 | Anguilla AL | 2008-04-30 00:00:00 | Albania AM | 2008-04-30 00:00:00 | Armenia AN | 2008-04-30 00:00:00 | Netherlands Antilles AO | 2008-04-30 00:00:00 | Angola AQ | 2008-04-30 00:00:00 | Antarctica (10 rows)
ビジネスプロセスの理解
ここまできたら、実際にモデリングを、、としたいところですが、ディメンショナルモデリングで重要なのは、ビジネスプロセスをデータモデルに落とし込み、ビジネスニーズに応えるところです。今回は、こんなビジネスニーズのようです。
- 製品カテゴリーとサブカテゴリー
- 顧客
- 注文状況
- 出荷国、州、都市
ファクトとディメンション
ここからが、ディメンショナルモデリングの肝になるfactとdimensionを定義します。
まず、factとは、ビジネスにおけるイベントを表します。今回の例だと、注文に関するデータがdimensionですね。
次に、factの定義です。factは、ビジネスイベントに情報を追加する、もしくは説明するための情報を示します。今回の例だと、注文日や顧客の属性、製品のカテゴリーなどがfactに該当します。
ここで重要なのは、dimensionもfactも非正規化するということです。これにより、テーブルの結合処理が減り、少ないテーブルで分析をおこなうことができるというメリットがあります。
factとdimensionイメージですが、SQL集計でいうところの、GROUP BYやWHEREに使用するデータがfact、SUMやCOUNTに使用するデータがdimensionだと理解しました。
いざ、モデリングへ
ディメンションテーブル
さて、いよいよモデリングのお時間です。すでにdbtモデルは定義されているのですが、一例として、ディメンションテーブルの一つであるdim_product.sqlの中身をみていきます。
dim_product.sqlの前半
with stg_product as ( select * from {{ ref('product') }} ), stg_product_subcategory as ( select * from {{ ref('productsubcategory') }} ), stg_product_category as ( select * from {{ ref('productcategory') }} )
前半部分では、3つのテーブルを参照しています。これらのテーブルは、商品の属性を表し、正規化されています。ディメンションテーブルは、ビジネス粒度にあわせて非正規化していきます。
dim_product.sqlの後半
select {{ dbt_utils.generate_surrogate_key(['stg_product.productid']) }} as product_key, stg_product.productid, stg_product.name as product_name, stg_product.productnumber, stg_product.color, stg_product.class, stg_product_subcategory.name as product_subcategory_name, stg_product_category.name as product_category_name from stg_product left join stg_product_subcategory on stg_product.productsubcategoryid = stg_product_subcategory.productsubcategoryid left join stg_product_category on stg_product_subcategory.productcategoryid = stg_product_category.productcategoryid
ここではサロゲートキーも定義されています。これは、ディメンションテーブルを一意に識別するカラムで、ファクトテーブルとの結合キーになります。
通常のDBでは、プライマリーキー(DWHでは、ナチュラルキーとよぶらしい)が、結合のキーになるのですが、データウェハウスでは、複数のデータソースからデータを格納するため、ナチュラルキーが重複したり、今後もユニークに使われ続ける保証がないため、DWH内のみで使用するサロゲートキーを作成します。
また、これがあることで、「どのカラムを使って結合するんだっけ?」ということを考える必要がなくなるので、分析が楽になります。
(ただ、ナチュラルキーを、そのままhash化して、サロゲートキーにするメリットはどこにあるんですかね?)
ファクトテーブル
次は、ファクトテーブルをみていきます。ファクトテーブルもディメンションテーブル同様に非正規化&サロゲートキーの作成なのですが、ファクトテーブルには、すべてのディメンションテーブルと紐づけるためのサロゲートキーを作成しています。
fct_sales.sqlの後半
select {{ dbt_utils.generate_surrogate_key(['stg_salesorderdetail.salesorderid', 'salesorderdetailid']) }} as sales_key, {{ dbt_utils.generate_surrogate_key(['productid']) }} as product_key, {{ dbt_utils.generate_surrogate_key(['customerid']) }} as customer_key, {{ dbt_utils.generate_surrogate_key(['creditcardid']) }} as creditcard_key, {{ dbt_utils.generate_surrogate_key(['shiptoaddressid']) }} as ship_address_key, {{ dbt_utils.generate_surrogate_key(['order_status']) }} as order_status_key, {{ dbt_utils.generate_surrogate_key(['orderdate']) }} as order_date_key, stg_salesorderdetail.salesorderid, stg_salesorderdetail.salesorderdetailid, stg_salesorderdetail.unitprice, stg_salesorderdetail.orderqty, stg_salesorderdetail.revenue from stg_salesorderdetail inner join stg_salesorderheader on stg_salesorderdetail.salesorderid = stg_salesorderheader.salesorderid
ここまで理解したら実際にdbtを実行します。
dbt run && dbt test
One Big Table (OBT)の作成
最後に、すべてのディメンションとファクトテーブルを結合し、大きなテーブルを作成します。
with f_sales as ( select * from {{ ref('fct_sales') }} ), d_customer as ( select * from {{ ref('dim_customer') }} ), d_credit_card as ( select * from {{ ref('dim_credit_card') }} ), d_address as ( select * from {{ ref('dim_address') }} ), d_order_status as ( select * from {{ ref('dim_order_status') }} ), d_product as ( select * from {{ ref('dim_product') }} ), d_date as ( select * from {{ ref('dim_date') }} ) select {{ dbt_utils.star(from=ref('fct_sales'), relation_alias='f_sales', except=[ "product_key", "customer_key", "creditcard_key", "ship_address_key", "order_status_key", "order_date_key" ]) }}, {{ dbt_utils.star(from=ref('dim_product'), relation_alias='d_product', except=["product_key"]) }}, {{ dbt_utils.star(from=ref('dim_customer'), relation_alias='d_customer', except=["customer_key"]) }}, {{ dbt_utils.star(from=ref('dim_credit_card'), relation_alias='d_credit_card', except=["creditcard_key"]) }}, {{ dbt_utils.star(from=ref('dim_address'), relation_alias='d_address', except=["address_key"]) }}, {{ dbt_utils.star(from=ref('dim_order_status'), relation_alias='d_order_status', except=["order_status_key"]) }}, {{ dbt_utils.star(from=ref('dim_date'), relation_alias='d_date', except=["date_key"]) }} from f_sales left join d_product on f_sales.product_key = d_product.product_key left join d_customer on f_sales.customer_key = d_customer.customer_key left join d_credit_card on f_sales.creditcard_key = d_credit_card.creditcard_key left join d_address on f_sales.ship_address_key = d_address.address_key left join d_order_status on f_sales.order_status_key = d_order_status.order_status_key left join d_date on f_sales.order_date_key = d_date.date_key
dbt_utils.star()を使用して、サロゲートキー以外を選択したテーブルになっています。(dbt_utils.star()最高です。)
このテーブルさえあれば
SELECT {興味のある粒度(ディメンション)}, SUM({興味のある指標}) FROM OBT GROUP BY {興味のある粒度(ディメンション)},
みたいに簡単に集計ができますね。
完成
完成したテーブルリネージがこちらです。 少しみにくいですが、ファクトテーブル1つ(fct)に対して、ディメンションテーブル(dim)が5つ、OBTがひとつ紐づく形になっています。(チュートリアルのリンク先には、もう少しわかりやすくのっています。)
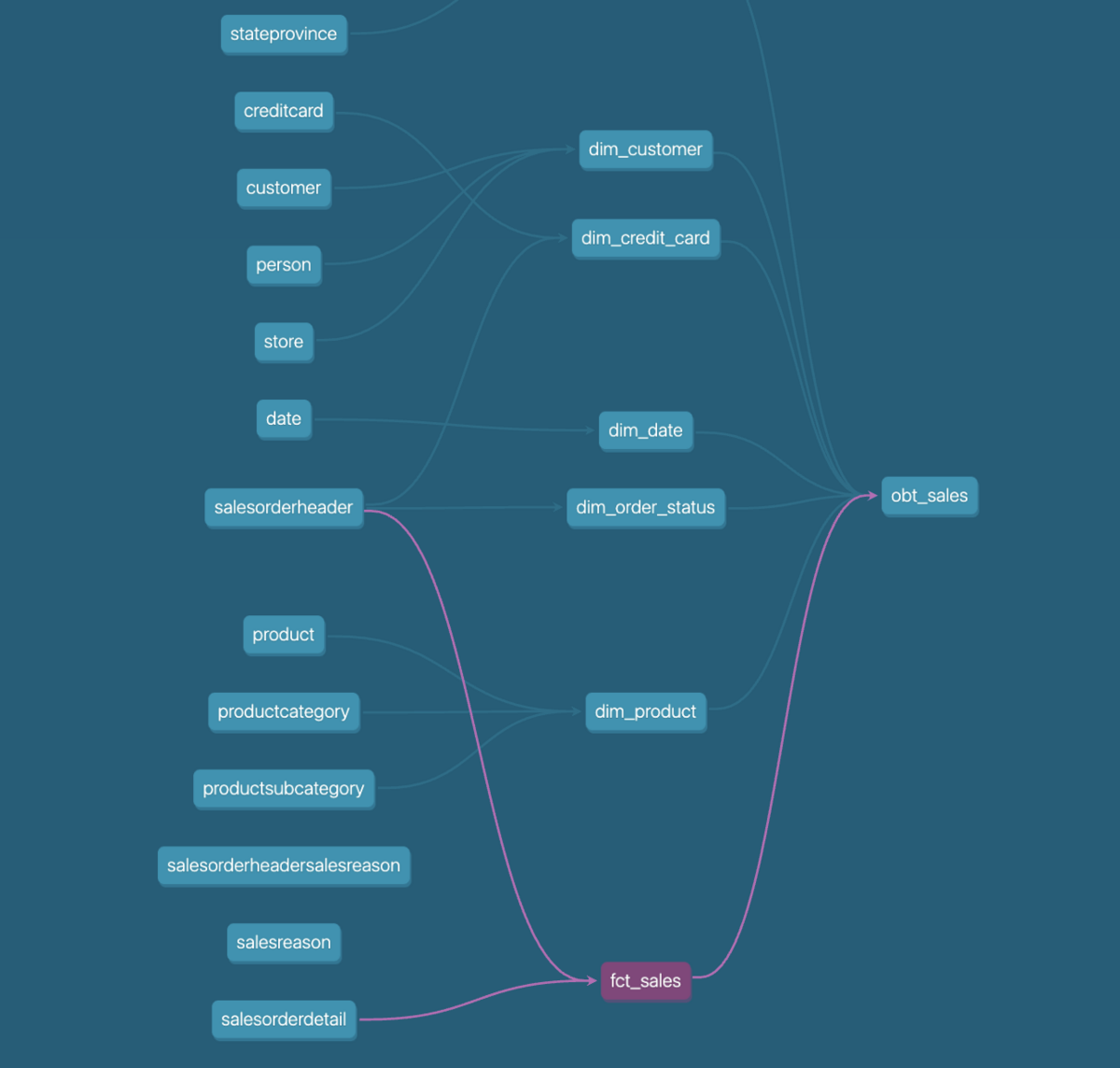
実際にCEOの要望に答えてみましょう。2011年におけるカテゴリーごと、サブカテゴリーごとの売上を集計しました。
-- カテゴリーごとの集計 select product_category_name, sum(revenue) as total_revenue from marts.obt_sales date_day >= '2011-01-01' and date_day <= '2011-12-31' group by product_category_name; product_category_name | total_revenue -----------------------+--------------- Accessories | 20825.0661 Bikes | 11836301.3995 Clothing | 36122.4344 Components | 639173.0405 -- サブカテゴリーごとの集計 select product_subcategory_name, sum(revenue) as total_revenue from marts.obt_sales date_day >= '2011-01-01' and date_day <= '2011-12-31' group by product_subcategory_name; product_subcategory_name | total_revenue --------------------------+--------------- Jerseys | 29558.5242 Mountain Bikes | 5578922.0274 Road Frames | 256210.1960 Road Bikes | 6257379.3721 Socks | 3743.665 Helmets | 20825.0661 Caps | 2820.2452 Mountain Frames | 382962.8445
まとめ
データウェアハウスにおけるDB設計は、サービスに紐づくバックエンドのDBの設計とは、思考回路が違うようです。ここが、バックエンドエンジニアと、データエンジニア(アナリティクスエンジニア)のスキルをわけるところになりそうですね。
今後は、ディメンショナルモデリングをさらに派生させたData Vaultなども調査していきたいです。
※本記事は筆者が個人的に学んだこと感じたことをまとめた記事になります。所属する組織の意見・見解とは無関係です。
参考
Building a Kimball dimensional model with dbt | dbt Developer Blog