本記事は、dbt advent calendarの内容です。 qiita.com
dbtは、データ基盤の開発に採用される事が多いと思いますが、 jinjaを使うことによって複雑な処理も実行が可能なため、データ解析系のプロダクトとも相性がよいです。
今回は、dbtを導入して、自社プロダクトに使われていた数十個のPythonスクリプトを撲滅した(い)という話をかいていきます。
自社プロダクトについて
弊社には、データサイエンス部が管理するクライアント向けのレポーティングプロダクトがあります。このプロダクトの機能は、以下のようなものです。
- クライアントから受領したデータをきれいに加工する。
- 加工したデータをつかって、クライアント向けのレポートを作成する。
- 要望によっては、アドホックな解析結果を追加する。
- データと解析スクリプトは、クライアントごとに切り分けて保存する。
クライアントごとにデフォルトで出力するレポート以外にも、個別ニーズに合わせて異なったデータセットやレポートを出力することもあるため、 マルチプロダクトな一面ももっています。
インフラ環境は、S3+Athenaで構築されており、その前後でPythonを使っています。
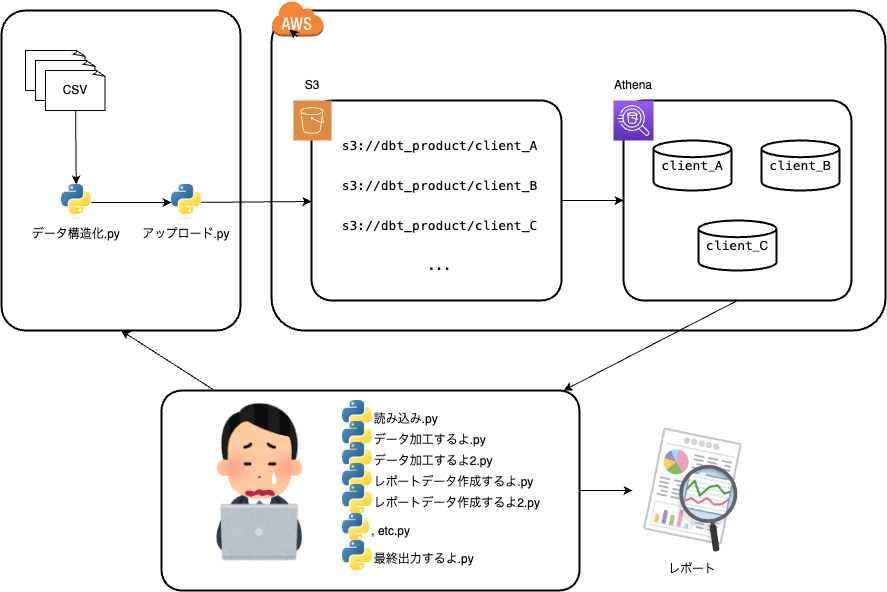
クライアントが少数&データサイエンス部が少人数であった時代から続くプロダクトのため、 両者の規模が大きくなるにつれて、以下のような課題が生じてきました。
- データ量が増大し、Pythonで処理することが難しくなってきた。
- Pythonスクリプトが複雑化し、特に新しいメンバーがメンテナンスするのが困難になってきた。
- クライアントのニーズが増えるにともなって、Pythonスクリプトも増加してきた。
このままでは、低パフォーマンスでありながら、だれもメンテナンスができないプロダクトになってしまう可能性がありましたので、 dbt & データモデリングを導入して、Pythonスクリプトを撲滅することにしました。
思想としては、すべての加工ロジックをdbtで管理し、最低限の読み込みと出力のみをPythonで実行することを目指しました。
具体的にどうしたか?
ETLからELT
まず着手したのがデータの入口部分です。今までは受領したデータは、Pythonで加工し、S3+Athenaに保存するETL方式になっていましたので、 増え続けるデータを処理するのには限界がありました。そこで、アップロードしてからをdbtをつかってAthenaで加工を行うELT方式に切り替えました。
要件として、各クライアントごとにデータベースを切り替えて、処理を行う必要があるため、データベース情報は以下のように環境変数を参照します。 また、dbt-athenaでテーブルを作成した場合に実体のあるデータとしてS3へ書き込まれるため、S3のパスにもクライアントごとの環境変数を使用しています。
# dbt_project.yml dbt_product: outputs: prod: aws_profile_name: athena database: awsdatacatalog region_name: ap-northeast-1 s3_data_dir: s3://dbt-product/{{ env_var("TARGET_ID") }}/tables # S3の保存先もクライアントごと s3_data_naming: table s3_staging_dir: s3://dbt_product/athena_log schema: '{{ env_var("TARGET_ID") }}' # ここを環境変数にする threads: 1 type: athena work_group: dbt_product
# source.yml source: - name: source_tables schema: '{{ env_var("TARGET_ID") }}' tables: - name: source_table1 - name: source_table2
また、Pythonでモジュール化されていた加工処理は、dbtのマクロで書き換えることで対応しました。 特に列名や型変換については、テーブルごとに変数で管理することで、SQLをシンプルにするようにしています。(以下簡略化した例)
-- 列名と型変化のマクロ {% macro convert_columns(column_mappings) %} {% for pre_col, details in column_mappings.items() %} CAST({{ pre_col }} AS {{ details.type }}) AS {{ details.new_col_name }} , {% endfor %} {% endmacro %}
# dbt_project.yml # 変数を辞書形式で格納する table_hoge: col1: {type: string, new_col_name: new_col1}
-- table_hoge.sql SELECT {{ convert_columns(var('table_hoge')) }} FROM table_hoge
これにより大規模なデータだと数時間かかっていた処理が、数十分で処理できるようになりました。
データモデリングとマルチプロダクト対応
次に、出力するレポートを作成する処理をdbtで書き換えました。ここでは、既存のPythonスクリプトと、SQLをにらめっこしながら、一つずつ処理を置き換えていく地道な作業の繰り返しです。
処理の整合性を担保するため、ブラックボックステスト形式で、既存処理との出力差異を細かくチェックしながら作業を進めました。
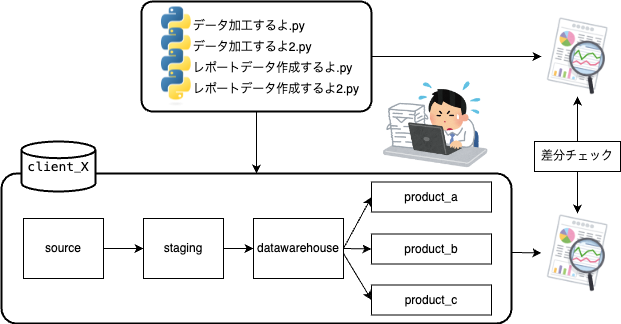
また、単に処理を置き換えるだけでなく、クライアントニーズにあわせた柔軟な対応を可能にするため、各種処理をディメンショナルモデリングに翻訳し、 拡張性のたかいデータ分析基盤を目指しました。
他のパターンでの出力については、フォルダ単位でモデルを切り分けて、tagで出力を制御するようにしています。こうすることで、新たなプロダクトが必要になっても、データウェアハウス層以降でモデルを増やしていくだけで拡張ができ、一つのデータ基盤をマルチプロダクトとして対応ができます。
moodels ├── staging ├── datawarehouse ├── products │ ├── product_a │ ├── product_b │ └── product_c | └── ... (追加可能)
# dbt_project.yml models: dbt_product: +materialized: view products: product_a: +tags: [product_a] product_b: +tags: [product_b, adhoc] product_c: +tags: [product_c, adhoc]
# 以下のように実行を切り替えて、dbtを実行する。 dbt run --exclude tag: adhoc # デフォルトプロダクトを実行するとき dbt run --select tag: produc_b # 追加プロダクトを実行するとき
また、モデル単位で依存関係がわかりやすいdbtでは、容易に既存プロダクトの改修ができますし、 dbtで置き換えたことにより、各種処理の単体テストもdbtで統一して行えるようになっています。
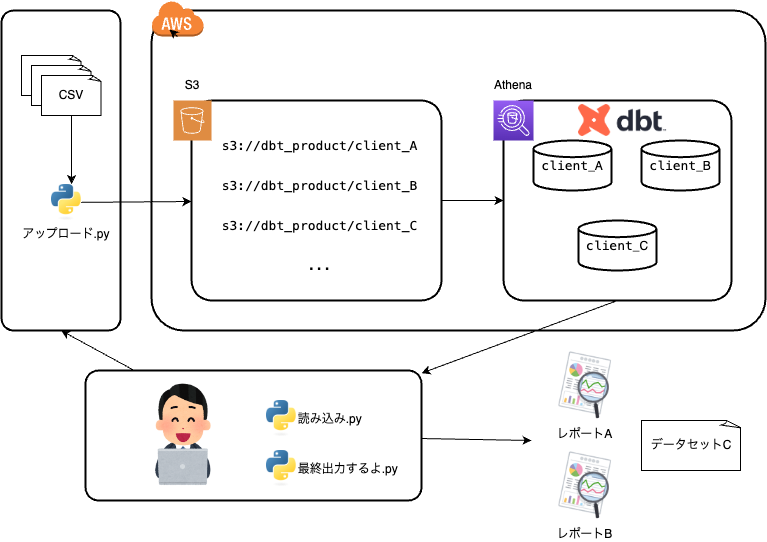
dbtを導入した現在地点と今後の課題
さて、ここまででdbtを導入して、多くのPythonスクリプトを撲滅することができました。まだまだ下流の処理で一部Pythonスクリプトが残っていますが、 そちらも今後はdbtで置き換えることになると思います。
最後に改めて、dbtを導入した現在地点と今後の課題をまとめます。
現在地点
- 加工ロジックの共有が楽になった。
- Pythonスクリプトに処理が包含されていると加工ロジックを理解、共有するのに時間がかります。
- dbtによって、すべての加工ロジックSQLで管理できるようになり、dbt docsで共有することで、知見の共有が楽になりました。
- メンテナンスのしやすさと拡張性が格段に高まった。
- Pythonという自由度を犠牲にすることで、メンテナンスのしやすさを向上させることができました。
- 追加ニーズに対しても、データウェアハウス層のテーブルを中心にテーブルを展開することで、拡張性を高めることができました。
- 解析知見の蓄積ができる環境がととのった。
- データウェアハウス層のテーブルだけでは対応しきれない場合は、アナリストがアドホックにSQLを書いて分析をします。
- その分析SQLをデータモデリングに反映させていくことで、解析知見がどんどん蓄積できる環境を整えることができました。
今後の課題
- データモデリングの更新
- データウェアハウス層は汎用性のある設計になっている一方で、すべてのニーズに答えられるようにはなっていません。
- そのため、個別のニーズから、都度テーブルを増やし、部分最適化されたデータモデリングになっている部分もあります。
- 部分最適化のモデルから、データウェアハウス層を見直し、データモデリングを更新することも必要になってくるでしょう。
- データ基盤のチーム開発
- データエンジニアが中心となってデータ基盤を整備していますが、アナリストの解析知見はデータモデリングにおいて必須です。
- 現在、データエンジニアとアナリストが協力して、データ基盤を整備する体制はととのっていないため、今後の課題となります。
- アナリティクスエンジニアを一つの職種としてきちんと定義する必要もでてくるかも
まとめ
dbtは、SQLを中心にデータモデリングができるため、アドホック解析と定義のかたまったデータ基盤の間を繋ぐことができると思っています。 一般的なデータ分析基盤での用途以外でも、定常で実施するような解析業務やレポーティング業務でも十分に力を発揮することができるので、 データ解析にプロダクト開発の要素を取り入れることができる可能性を秘めていると感じます。
今後も、dbtを使ってPythonコードの撲滅を進めていきたいと思います。