
Rでテーブルを縦持ち、横持ちに変換したい時、以前は、spreadやgatherという関数がありました。(今もあるのですが、)上記2つに代わって新たに上位互換の関数として登場したのがpivot_longer、pivot_widerです。単純に縦持ち、横持ち変換するだけでなく、列同士の結合や、集計など行うこともできます。
dplyrを使ったその他の前処理方法を知りたい方や、Pyhonで実行したいという方はこちらをご覧ください。
データの作成
まずはデータの作成を行います。作成するデータは、ある架空3店舗の顧客数を日ごとにカウントしたデータです。その日の天気も格納されています。このデータを使って、縦持ち、横持ち変換を行ってみましょう。
# パッケージの読み込み library(tidyverse) library(lubridate) set.seed(10) # データ作成 df <- tibble( date = format(seq(ymd("2020-1-1"), to=ymd("2020-1-10"), by="day"), "%m/%d"), weather = sample(c("sunny", "rainy", "cloudy"), size=10, replace=T), id_A = round(rnorm(60, 10, n=10)), id_B = round(rnorm(60, 10, n=10)), id_C = round(rnorm(60, 10, n=10)) ) df %>% head(10)
| date | weather | id_A | id_B | id_C |
|---|---|---|---|---|
| 01/01 | cloudy | 56 | 58 | 51 |
| 01/02 | sunny | 44 | 69 | 59 |
| 01/03 | rainy | 57 | 65 | 57 |
| 01/04 | cloudy | 71 | 54 | 41 |
| 01/05 | rainy | 68 | 38 | 59 |
| 01/06 | cloudy | 58 | 53 | 70 |
縦持ち変換(wide to long)
データは3店舗が横並びになっています。これを縦持ちに変換してみましょう。
df %>% pivot_longer(cols = c("id_A", "id_B", "id_C"), # 対象列 names_to = "store", values_to = "customer")
| date | weather | store | customer |
|---|---|---|---|
| 01/01 | cloudy | id_A | 56 |
| 01/01 | cloudy | id_B | 58 |
| 01/01 | cloudy | id_C | 51 |
| 01/02 | sunny | id_A | 44 |
| 01/02 | sunny | id_B | 69 |
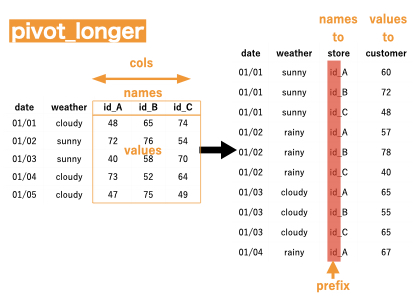
店舗と売り上げがそれぞれの縦持ちの形になりましたね!ただ、"id_"という文字が邪魔なので、消したいですね。そんな時はname_prefixを使うと接頭語を削除して、namesカラムに値が入ります。ここには、正規表現が使えるので、どんな接頭語でも対応できます。
df %>% pivot_longer(cols = c("id_A", "id_B", "id_C"), # 対象列 names_to = "store", names_prefix = "id_", values_to = "customer")
| date | weather | store | customer |
|---|---|---|---|
| 01/01 | cloudy | A | 56 |
| 01/01 | cloudy | B | 58 |
| 01/01 | cloudy | C | 51 |
| 01/02 | sunny | A | 44 |
| 01/02 | sunny | B | 69 |
引数の意味がわかりにくいですが、イメージとしては、このようになっています。
横持ち変換(long to wide)
今度は、横持ちに変換してみましょう。先程の逆バージョンですね。namesが横持ちのカラムに、valuesがそのカラムの値となります。
# 縦持ちに変換しておく df_long <- df %>% pivot_longer(cols = c("id_A", "id_B", "id_C"), names_to = "store", values_to = "sales") # 横持ち変換 df_long %>% pivot_wider(names_from = "store", values_from = "sales")

少し高度な使い方
pivot_widerでは、エクセルのピボットテーブルのように集計を行うこともできます。ここでは、天気ごとの平均顧客数や合計顧客数を算出してみます。
# 合計 df_long %>% # 日付情報は関係ないので消しておく select(-date) %>% pivot_wider(names_from = "store", values_from = "sales", values_fn = sum) # A tibble: 3 x 4 # weather id_A id_B id_C # <chr> <dbl> <dbl> <dbl> #1 cloudy 433 360 380 #2 sunny 44 69 59 #3 rainy 125 103 116 # 平均 df_long %>% # 日付情報は関係ないので消しておく select(-date) %>% pivot_wider(names_from = "store", values_from = "sales", # functionを入れることもできる。 values_fn = function(x) round(mean(x), 1)) # weather id_A id_B id_C # <chr> <dbl> <dbl> <dbl> # 1 cloudy 61.9 51.4 54.3 # 2 sunny 44 69 59 # 3 rainy 62.5 51.5 58
各天気ごとの合計や、平均が出ましたね!
まとめ
spreadやgatherはまだ使えるようですが、より応用範囲の広いpivot_longer、pivot_widerに使い慣れていきたいですね。
※本記事は筆者が個人的に学んだこと感じたことをまとめた記事になります。所属する組織の意見・見解とは無関係です。
参考
Tokyo.Rでtidyr::pivot_longer()、tidyr::pivot_wider()について発表してきました - Technically, technophobic.
Pivot data from wide to long — pivot_longer • tidyr
![RユーザのためのRStudio[実践]入門−tidyverseによるモダンな分析フローの世界−](https://m.media-amazon.com/images/I/51yOW-20h-L.jpg "RユーザのためのRStudio[実践]入門−tidyverseによるモダンな分析フローの世界−")